Generating Unsupervised Ways to Die: The Making of a D&D Monster Generator

About 6 months ago, I had some downtime while transitioning jobs and decided to look for a project to entertain myself with. I had previously run into Minamaxir’s GPT-2 Magic Card Generator and thought it could be quick and fun to apply that idea to a hobby of my own, Dungeons and Dragons. Such a generator could end up being a useful tool, but more likely I figured I would end up with a toy project to play with while quickly teaching myself a little more about GPT-2. Unfortunately, it didn’t end up being quite as simple as I had imagined.
The Model
For synthetic text generation, there are only a few machine learning techniques which have shown significant promise. Foremost among these is OpenAI’s GPT-2. If you’re unfamiliar with GPT-2, you might want to click through that link and read their explanation of it before proceeding. As a one line summary, the GPT-2 transformer model was trained to simply predict the next word in a text, given all previous words. There are numerous examples where it performs uncannily well. Most applications I have seen, however, generate unstructured text of fairly short lengths, no more than about a paragraph. D&D monster stat blocks, in contrast, are well-structured and can be fairly lengthy, with the longest taking up full pages in the rather large-paged books they come in.
If I wanted to create a model that would create D&D monsters, the first order of business would be to procure machine-readable monster data. While I own a couple of source books, the task of translating them from physical to digital text was one I was hesitant to take on. Luckily, there are numerous 5th Edition D&D (5E) resources online and I was able to easily find a JSON-formatted list of every 5E monster to date. Once I had this, I spun up a Google Colab instance and began training. For training, I turned again to Minamaxir, using his gpt-2-simple library. This is where I hit my first problem. GPT-2 produces fixed-size output tensors of size 1024, which in practice means that the output size is limited to 1024 tokens (essentially, characters, but with some longer substrings compressed to single values). Much of the monster data I had, even when stripped of unnecessary tokens and formatting, was longer than this.
Furthermore, the most interesting monsters tend to be the ones with longer stat blocks. I was confident that this wasn’t going to be a dead end. There had to be a solution to creating longer text blocks with GPT-2, if only I could find it.
A pull request to gpt-2-simple provided the answer I was looking for. The author proposed feeding generated results as context for another generation pass. This enabled the model to continue from where it left off at the cost of progressively forgetting the context that came before. Unfortunately, that latter drawback appears to be a necessary evil when working with GPT-2 for long-form generation like this. Though the pull request didn’t work for me, I was able to replicate the idea. It broke batch generation, preventing me from making my own pull request, but it was enough for me to train the model and start generating monsters. To my surprise, not only was the model able to create well-formatted JSON, in most cases where it failed to do so, the results were fixable with only one or two modifications. Indeed, I was able to write a script to fix many of these simple errors. This held even for longer stat blocks where, by necessity, GPT-2 would lose the context of the outermost opening curly braces by the time it reached the corresponding closing curly brace. I hypothesized this was because the model had the spacing of pretty printed JSON to work with, combined with a consistent ordering in fields. The model didn’t need to know about the actual rules of JSON if it knew that after every “action” block was a right curly brace at zero level of indentation. Testing bore this out. When I removed formatting, the error rate at temperature 1.0 (temperature being a variable GPT-2 uses that roughly corresponds to variance) jumped from about 1 in 4 to about 3 in 5. Furthermore, my script dropped from being able to fix about 2 in 3 errors to being able to fix only about 1 in 4. Clearly the indentation was helping a lot.
Though the model was able to create well-formatted JSON right out of the gate, there were still a couple of obvious flaws. First and foremost, the generator had an unfortunate tendency to lose track of what sort of monster it was making partway through. Something that started off as a dragon might suddenly begin referring to itself as an orc by the time you reach the action block, losing all coherence in the process. The second flaw was a little more subjective–the results seemed to represent an overfit. While it can be desirable for many abilities to be exact copies (the Magic Resistance trait, for instance, is only ever printed one way), the generator was often recreating stat blocks wholesale.



It was easy to address the generator losing monster names as it went along, though ultimately impossible to fix outright. By seeding the name of the creature throughout the training data, I was able to keep the name in the generator’s context throughout generation. This proved to be enough in most cases, but the nature of the model is such that the name itself would sometimes be mutated, causing a cascade downward. It is plausible that by simply scaling up the size of the GPT-2 model used (I used 117M, the smallest size), this issue could be further mitigated. That might, however, exacerbate my other problem — the overfit issue.
The two simplest ways to address overfit are to either train for fewer cycles, or get more data. I found that training less resulted in a higher proportion of malformed JSON results, so I opted to find more data instead. However, the number of monsters in 5E is limited, and new ones come out slowly. (There were a little over a thousand at the time I trained the model). Luckily, there is an absolute glut of homebrew content available online. Unfortunately, this content is rarely JSON-formatted, and does not always follow the exact formatting rules the official monsters do. This made it comparatively difficult to ingest. Despite this, I decided to (politely) scrape DNDBeyond’s homebrew section for all of its monsters above a certain ranking, and then wrote a very manual script to painstakingly convert them from HTML to JSON. Because certain blocks (spellcasting in particular) did not have standard formatting, this task proved to be particularly tedious, if ultimately successful. With these new monsters in hand, I had about tripled my dataset. I did ultimately write a sampler which takes from this dataset at a lower proportion than the canonical monsters, since I disliked some of the output inconsistencies from it.
This sampler works simply. At each generation of training, GPT-2 randomly picks a chunk of text 1024 characters long out of the training data. I added a preprocessing step before that which selects from two training datasets with a weighted random chance. Subjectively, the results for this were best at 65% official and 35% homebrew.
At this point, I had a working model. It was already able to generate novel results, and it output well-formatted JSON with high probability. Now, it was time for a front-end. For this, I enlisted the help of a good friend, Ellis Tsung, who drew heavily from the 5E official styling to create monster blocks that look almost identical to what you’d see in the source material. It’s really quite impressive.

Deployment
The last step was deployment. This turned out to be a gigantic issue. I spent some time trying to coerce the model output into something usable by Tensorflow Serving, but since GPT-2-Simple was not written for Tensorflow 2, this proved extremely difficult. It would have been cool (and cost-effective) to be able to use Serving to offload GPU computation onto AWS’s Elastic Inference or a similar service. Unfortunately, after about a week of abortive attempts, I started at my new job, and things fell off for a while.
Eventually I got sick of having this project sit unfinished. Tensorflow Serving was beyond me, at least for the moment, but there were several other less exciting options I could use for deployment. While AWS Spot Instances wouldn’t allow for quite the same amount of savings, they did give me access to g4dn.xlarge inference-optimized GPU instances. The inherent cost of GPUs meant this wouldn’t be cheap, but the speedup these instances offered over CPU-based inference was well worth the price of doing business. With these instances as my base platform for deployment, I now had to put together a solution that could stay available and scale under load. I wasn’t expecting it to handle several thousand concurrent views, but I wanted to ensure the site was able to stand up under at least a few dozen.
There are, of course, numerous ways to deploy a project like this. I decided on a mix between something new and something comfortable by picking AWS’s Elastic Container Service (ECS). Kubernetes would probably have been the best choice, but at this point I just wanted to complete this project, and I was already decently familiar with using ECS through Fargate. Since ECS only allows GPUs through EC2 deployment (rather than Fargate) I would still have an opportunity to learn something new.
ECS turned out to be a frustrating choice. Containerization and the various networking concerns like DNS and HTTPS proved to be time-consuming to understand but ultimately straightforward. Autoscaling proved to be quite the opposite — overtly simple yet anything but straightforward. As far as I can tell, the way autoscaling is meant to work for this type of deployment is as follows. First, you create an autoscaling group in EC2. Then, you give ECS control of said group, and set rules through ECS. What happened in practice, from what I could tell, is that I made ECS aware of the EC2 autoscaling group, which allowed the former to place containers on the latter. However, ECS did not attempt to scale out the EC2 group, and when the EC2 group scaled out, the ECS service did not necessarily place containers on the newly created instances. Conversely, when ECS wanted to scale, it would complain there were no appropriate instances on which to place a new container, rather than prompting the creation of one. Even though I had a very simple deployment (1 container per instance, since each container needed one GPU), I was unable to get these two parts to properly interface. Ultimately, by just scaling on the same rule (CPU usage) I was able to get the scaling to synchronize. Such a solution was kludgey, however, and more fragile than I had hoped for.
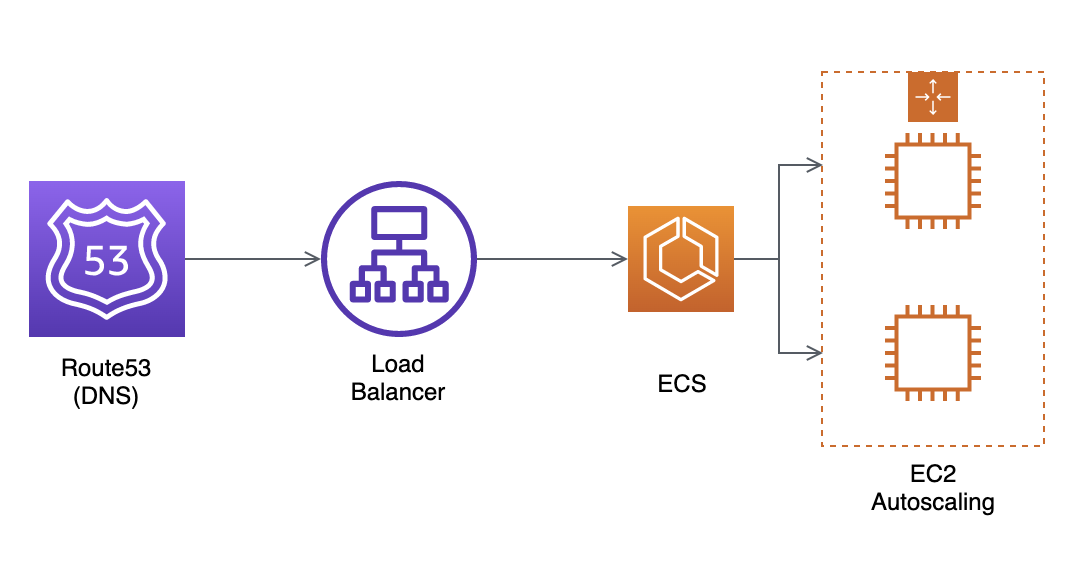
With scaling (such as it was) in place, I felt ready to put the project out in the world. I opened up the AWS security groups, posted the website on Reddit, and saw… moderate interest. It garnered a few hundred upvotes on the D&D homebrew subreddit, /r/unearthedarcana, and I saw perhaps a dozen concurrents at peak. I have to admit, this was a little disappointing, but ultimately I was glad it didn’t entirely flop.
Setbacks aside, this was a very enjoyable project. I should note that I don’t think that there is a particular need in the D&D community for a monster generator. In fact, I find that creating monsters is a delicate enough task that it would be negligent to leave solely to an algorithm with no concept of balance. In that regard this tool is, at best, an inspiration generator… and a very fun toy. The results it comes up with can be hilarious and surprising. All told, this was a great opportunity for me to wade into the depths of model training and deployment, and helped me build a deeper understanding when it comes to productionizing modern machine learning. Hopefully this has inspired you to try your own ML experiments, and hopefully you can appreciate the occasional cleverness (and mountain of silliness) my project produces.